Share Features
The Tecton Framework is designed to simplify sharing features across multiple downstream models. Sharing features between models can help save on the cost it takes to develop, compute, and store feature data.
This guide covers common patterns in feature sharing, and how Tecton facilitates them.
Feature Sharing Patterns
Many organizations leverage the Tecton platform today to share features between models. The most common sharing patterns are:
- Sharing features across model iterations: For example, a data scientist may be testing a few new user features to improve their model performance, but the existing 95% of features remain the same. The ability to easily re-use the features from the existing model version significantly reduces the time and cost it takes to launch the new experiment, enabling the data scientist to run more experiments and ultimately deliver greater model improvements.
- Sharing features across models in the same domain: For example, the Recommendations team for an e-commerce site may have one product recommendation model for the home page, and another for the checkout screen. Because the model objective between these two product surfaces are similar, likely many of the same features will be valuable. Sharing features between related models can reduce the costs of running these models, and save the Recommendations team time on developing and maintaining redundant feature pipelines.
- Shared core application features: Features that capture basic context about an applications, such as the age of a user account, may be valuable for a broad range of use-cases. Often these features are created and managed by a centralized platform team, and consumed by model developers across several teams. By making a library of standard features available for use, new ML teams can stand up models more quickly. Additionally, the platform team benefits from a reduced surface area maintenance and compliance.
How to share features in Tecton
The Tecton framework inherently decouples feature computation, as Feature Views, from feature consumption, as Feature Services.
As soon as a developer has contributed a Feature View to a Workspace, it’s ready for re-use! The Feature View can automatically be referenced by multiple Feature Services without any duplication of resources.
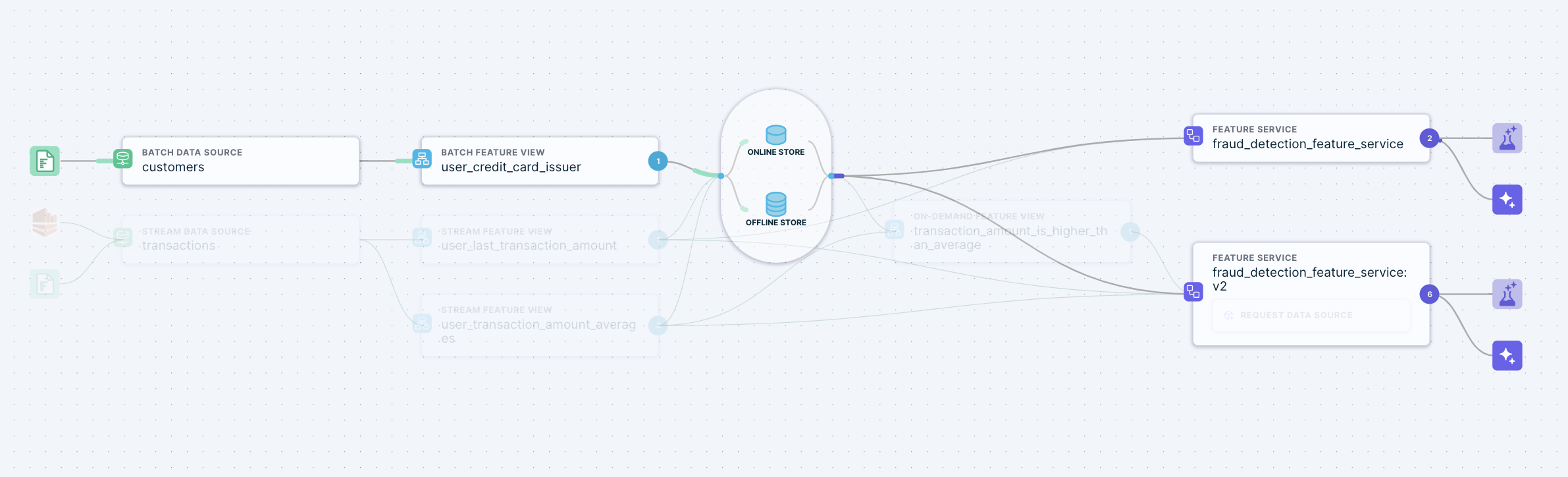
The following example shows a simple Batch Feature View that is used as an input for two iterations of a fraud detection model.
@batch_feature_view(owner="fraud-platform", entities=[user], source=customers)
def credit_card_issuer(customers):
return f""" SELECT user_id, credit_card_issuer, ts FROM {transactions}"""
fraud_detection_feature_service = FeatureService(features=[credit_card_issuer, user_last_transaction_amount])
fraud_detection_feature_service_v2 = FeatureService(
features=[credit_card_issuer, user_last_transaction_amount, user_transaction_amount_averages]
)
Once applied, the Tecton Dataflow diagram illustrates how the
credit_card_issuer Feature View is an input for both Feature Services.
Advantages of features sharing with Tecton
Features-as-code framework enables safe feature sharing
A common fear with feature sharing is that the original developer may modify or delete the upstream feature pipeline, and unknowingly break some other downstream models.
With Tecton’s features-as-code framework, consumers of the Feature View are
explicitly tracked in code through the Feature Service. If the Feature View is
modified in a way that would impact the feature definition, the tecton plan
will automatically highlight all impacted feature consumers. The feature
developer can then contact the appropriate owners of those consumers by
inspecting the Feature Service metadata. Finally, tecton apply will require
explicit acknowledgement by the user or CI/CD process of the downstream impact
before rolling out the change.
As a best practice, most organizations leverage CI/CD processes for their Tecton feature repositories to prevent accidentally releasing feature updates that break downstream models.
Data model optimized for cost optimized sharing
Computing and storing features can be the biggest infrastructure cost for production AI applications. Often computation and storage is much more expensive than reading features!
The Tecton data model promotes modular storage of the features in a model as Feature Views. Because a Feature View only stores the features once, even when referenced by multiple Feature Services, all the cost to calculate and store the features is saved when adding subsequent models.
Furthermore, the Tecton Feature Serving Cache is optimized for sharing **cached****** features between models, so that the same cache can be used by multiple models. This shared cache has multiple benefits:
- Lowers cache costs by needing less expensive memory to store duplicate feature values.
- Lowers Feature Serving costs by increasing cache hit rate.
- Improves a/b test accuracy by providing consistent read-time performance. If the cache was not shared, then the new model would be at a latency disadvantage due to a lower cache hit rate!