LLM Prompt Engineering
Production generative AI systems, such as Large Language Model (LLM) driven systems, need access to rich context to tailor their interactions with the end user. This page gives an overview of how to use Tecton for prompt engineering to significantly improve LLM model performance.
Context-poor vs Contextual prompts and LLM performance
Let's look at a use case of generating a credit card recommendation using an LLM.

The response with a contextual prompt is significantly better than a context-poor prompt, because a contextual prompt gives the LLM the important signals for determining the right recommendation. In fact, getting the context correct and upto date is a critical piece in LLM performance.
Contextual Prompts with Tecton
Tecton is designed to automate the complete lifecycle of prompt context needed for operationlizing generative AI at scale. Tecton enables teams to build, automate, and centralize data pipelines for prompt context for LLMs with remarkable speed, ease, and enterprise-grade reliability.
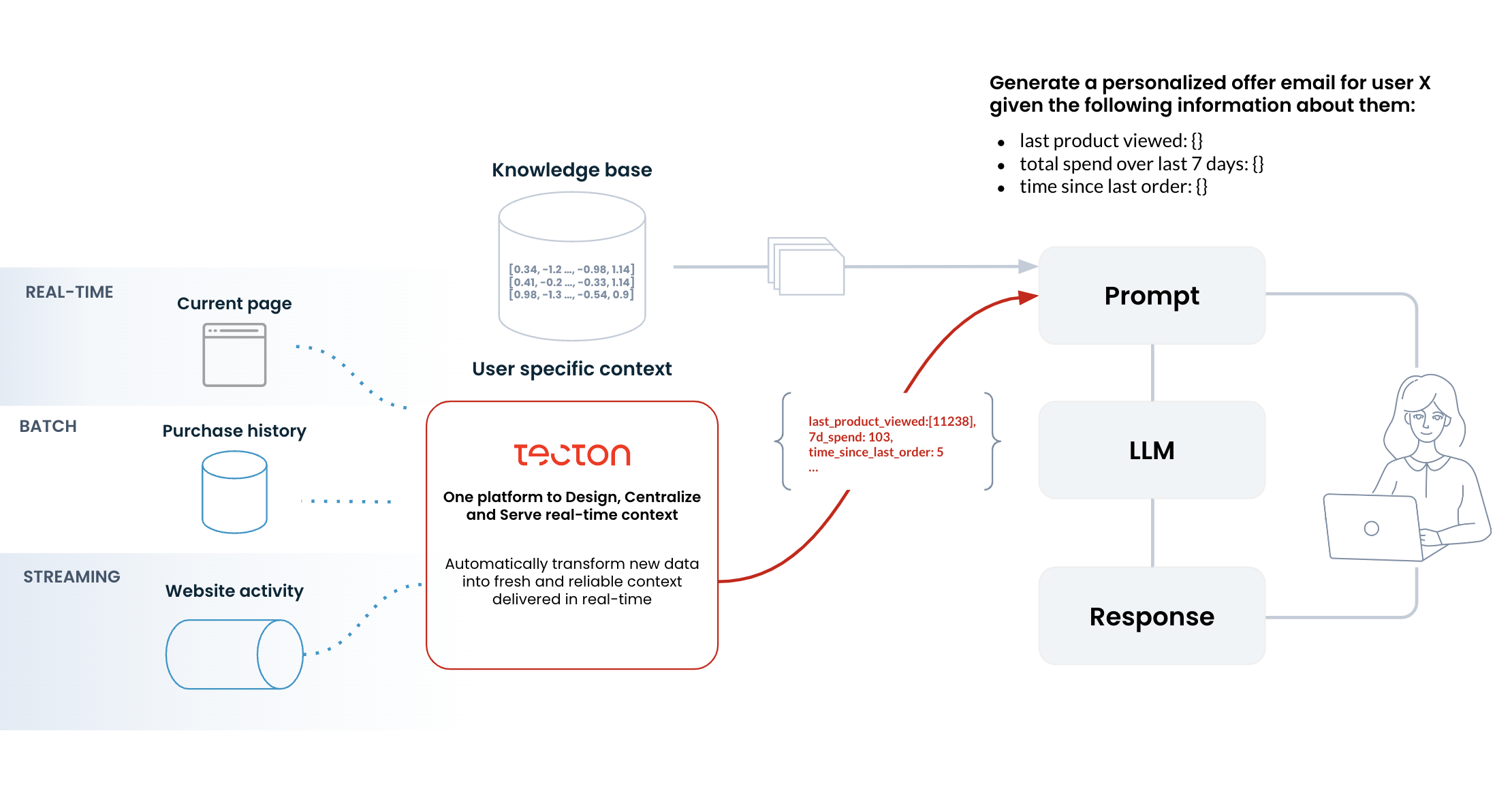
Tecton addresses the full range of challenges in building and maintaining LLM context features: defining, testing, orchestrating, monitoring, and managing the context features.
By leveraging Tecton for prompt engineering, you can extract powerful insights from customer events as they unfold in real time and pass those as signals to LLMs to tailor the interaction with the end user, which in turn makes the business process much more performant.
For a code example for generating contextual prompts see the guide for Generating Contextual Prompts with On-Demand Feature Views.